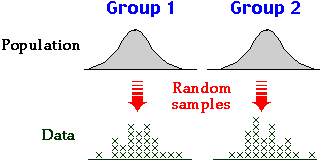
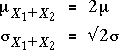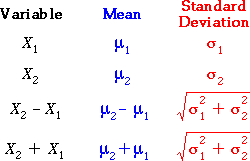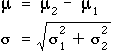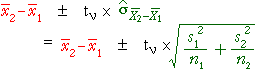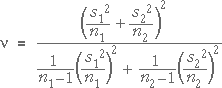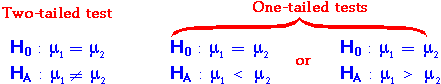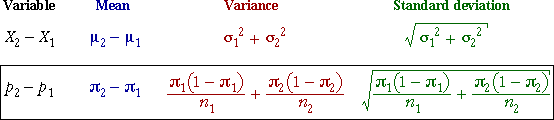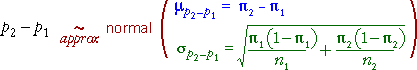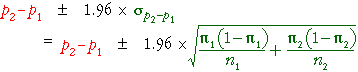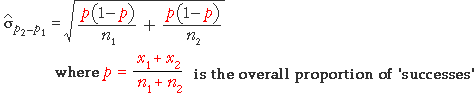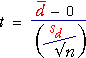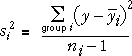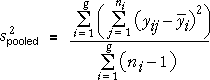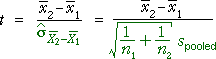We often want to compare individuals (or other units) from two groups. If a numerical
value is recorded from each individual, the resulting data consist of two batches of
numbers — one from each group.
Differences between the distributions of values in the two groups are often of interest.
'Individuals'
Measurement
Groups
Question
Customers in a supermarket
Amount spent (dollars)
Male and female
Do male and female customers spend the same amounts?
Bank accounts
Number of transactions in month
Two types of account with different fee structures (one with lower per-transaction
charge and the other with lower fixed charge)
Are there more transactions in accounts with lower per-transaction charges?
By how much?
'2 litre' milk containers filled in bottling factory
Volume of milk in container
Two different filling machines
Do both machines fill the containers with the same amount of milk on average?
Questions are often about underlying populations
The questions in the above scenarios are not about the specific
customers who entered the supermarket, the specific bank accounts
that were sampled, etc. They ask about the differences between supermarket spending by males and females in general, the differences between the two types of bank account
in general, etc.
We are therefore usually interested in the characteristics of a population
or process that we assume underlies the data that are collected.
The data provide information about the likely characteristics of the population.
Examples
The diagram below shows a few data sets in which values are in two groups.
Note that the red questions do not refer to the specific individuals in the
study, but ask about differences between the groups 'in general' — we would like
to use the answers to predict what will happen to other individuals.
11.1.2 Model for two groups
Histograms of data in each group
When data are collected from two groups, a histogram can be used to graphically
display the distribution of values in each group.
End-of-year bonuses paid to lower-level executives
A company has a generous but rather complicated policy on end-of-year bonuses
for its lower-level managerial personnel. A key factor of the policy is a subjective
judgement of 'contribution to corporate goals'. The diagram below shows the bonuses
awarded to the 24 female and 36 male executives. The crosses have been jittered
a little (randomly moved) to separate them in the scatterplot.
This diagram is 3-dimensional. Position the mouse in the middle of the diagram
and drag towards the top left of the screen to rotate the plot
(or click the 3D rotation button). The histogram within each group describes the
distribution of bonuses awarded to that gender.
Model for each group
A single batch of numerical values is usually modelled as a random sample from
some population — often a normal distribution. In a similar way, data sets that
consist of measurements from two groups are often modelled as two independent random samples from two underlying
hypothetical infinite populations. Normal distributions are again commonly used
as models.
(The assumption of normality should be checked from graphical
displays of the sample data. If the data are noticably skew, a transformation may provide
values that can be adequately modelled by normal distributions.)
End-of-year bonuses
The histograms of bonuses paid to male and female executives both seemed fairly
symmetrical, so normal distributions are reasonable models within the two groups.
The diagram below shows a possible model for the bonus data.
Click Take sample to select a random sample from each of the
two normal distributions. The model claims that the real data
set consists of random samples from distributions like these.
11.1.3 Parameters of the normal model
Parameters
A normal model for two groups has four unknown parameters (the mean and standard
deviation for each normal distribution). These parameters give considerable flexibility
and allow the model to be used for a variety of different data sets.
(If the standard deviations in the groups are assumed
to be equal, the number of unknown parameters can be reduced to three, but
we will not consider models of that form until a later section.)
Illustration
The following diagram shows the flexibility of this class of models
Use the four sliders to adjust the four parameters of the model. (Note
that the relative heights of the normal curves change as the scale parameters
are adjusted to maintain equal areas for the two normal curves.)
Click Take sample a few times to see typical data sets that arise from the model. The blue bands at the base of the normal distributions are at µ ± 2σ so they include about 95% of the sample values in each group.
11.1.4 Parameter estimates
Objective parameter estimates
A normal model for 2-group data involves 4 unknown parameters, µ1,
µ2,
σ1 and σ2.
The means and standard deviations in the two samples provide objective
estimates of the four parameters.
Examples
The following diagram shows the 'best' estimates of the parameters for a few data sets.
11.1.5 Difference between means
Comparing the populations
For two-group data sets, we usually want to compare the underlying populations.
In particular, the main questions of interest are:
Are the two population distributions the same?
If the populations are different, how big is the difference?
Comparing the population means
The two standard deviations in the groups may differ. However we are usually
more interested in differences between the population means. The earlier questions
can be asked in terms of the difference between these means,
If the group means are equal (and µ2 - µ1 is therefore zero), then values from neither group are higher than from the other,
on average. Indeed, if the distributions are normal and σ1 and σ2 are also equal, then a zero value for µ2 - µ1 also implies that the distributions in the two groups are identical.
µ2 - µ1
describes how much higher the values in group 2 are (on average) than the values
in group 1.
The best estimate of µ2 - µ1 is, naturally, the difference between the means of the two samples, .
Randomness of sample difference
Unfortunately,
cannot give a definitive answer to questions about µ2 - µ1 since it is a random summary statistic — it varies from sample to sample. The
distribution of
must be understood before we can make any inference about µ2 - µ1.
Simulation: Manipulative skills of job applicants
To test the manipulative skill of job applicants, they are sometimes given
a 'one-hole test' in which they grasp a pin, move it to a hole, insert it, and
return for another pin. The test score is the number of pins inserted in a fixed
time interval. A large study was undertaken comparing male college students with
experienced female industrial workers. The table below describes the number of
pins inserted in one minute.
Group
n
mean
s
Male college students
750
35.12
4.31
Experienced female industrial workers
412
37.32
3.83
We will conduct a simulated experiment based on this scenario. In the simulation,
we will generate 'numbers of pins' for 40 male students from
a normal distribution with µ2 = 35.12
pins and σ2 = 4.31
pins and similar data for another 40 experienced female workers
from a normal distribution with µ1 = 37.32
and σ1 = 3.83.
Note that the female industrial workers, on average, insert µ2 - µ1 = 2.20
more pins than the male students.
(The normal distributions from which the data are sampled are represented by a pale blue band at µ ± 2σ. The narrower darker blue band includes half of the population distribution.)
Click Accumulate, then take several samples. Observe that
the difference between the sample means is a random quantity whose distribution
is centred on µ2 - µ1 = 2.20
pins .
The difference in means from a single data set, ,
is therefore an estimate of µ2 - µ1,
but is unlikely to be exactly equal to it.
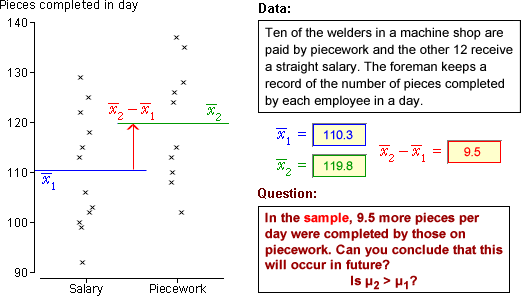
Welders who are paid a salary and those on piecework
In practice, the underlying population means (and their difference) are unknown,
and only a single sample from each group is available. The data set below is a
typical example.
Without an understanding of the distribution of ,
it is impossible to properly interpret what the sample difference, 9.5 pieces,
tells you about the difference between the underlying population means.
11.2 Distn of sums and differences
Means and sums of samples
Sum and difference
Sum and difference (cont)
Probabilities for sums and differences
11.2.1 Means and sums of samples
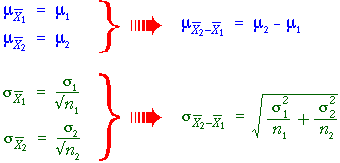
Distribution of a sample mean
In an earlier
section, we explained that the mean of a random sample, ,
has a distribution whose mean and standard deviation depend on the population
mean, µ,
and standard deviation, σ,
The standard deviation of the sample mean decreases
as n increases.
Also, irrespective of the population distribution, the shape of the distribution
approaches a normal distribution as the sample size, n, increases (Central
Limit Theorem).
Sum of values in a random sample
A sample mean is often the most descriptive summary statistic for a random
sample, but occasionally the sum of the sample values is more useful. For example,
if the individual values in a data set are the amounts paid by customers in a
supermarket during one day,
The mean (and standard deviation) are useful descriptions of a 'typical' customer.
The sum of the values is the total money paid by customers in the day.
The sum of sample values is n times their mean, so its distribution
is a scaled version of the distribution of the mean — the same shape but different
mean and standard deviation.
Its distribution also approaches a normal distribution as n increases.
It is important to note that, in contrast with the sample mean,
The standard deviation of the sample sum increases
as n increases.
Simulation to illustrate distributions of sample mean and sum
The diagram below allows samples of different sizes to be selected from a standard
normal distribution (with mean 0 and standard deviation 1).
The theoretical normal distribution of the sample mean is shown in blue, and
that of the sum is shown in green. Observe that the sample mean has lower spread
than that of the sample sum.
Click the checkbox Accumulate then click Take sample
a few times to select different samples of size 4. Observe that the sampling distributions
match these theoretical distributions reasonably well.
Repeat with different sample sizes.
11.2.2 Sum and difference
Sum of two identically distributed variables
We now concentrate on the sum of two independent random quantities
with identical distributions — e.g. a random sample of size 2 from a distribution
with mean µ
and standard deviation σ.
From the formulae on the previous page, this has mean and standard deviation:
Sum of two variables with different means
We now generalise by allowing X1 and X2 to have different means, µ1 and µ2,
but the same standard deviation. Their sum has a distribution with the same spread
as above, but the formula for the mean must be generalised:
Difference between two variables
A similar result holds for the difference between X1
and X2. If they both have standard deviation σ, their difference has the same standard deviation as their sum (but the distribution has a different mean):
Shape of distribution
If X1 and X2 are independent and have normal distributions, their sum and difference are also normally distributed.
If X1 and X2 have distributions with different shapes, their sum and difference usually have distributions that are non-normal but are closer to normal than the two source distributions. However the above formula for the mean and standard deviation hold whatever the shapes of the distributions of X1 and X2.
Illustration
The top of the diagram below shows the distributions of two normal variables, X1 and X2. The longer vertical red lines above each distribution can be dragged to adjust their means; dragging the shorter red lines changes the common standard deviation.
The bottom of the diagram shows the distribution of X1 + X2. Note that its mean is µ1 + µ2 and its standard deviation is √2 = 1.414 times that of X1 and X2. Change the means and standard deviations of X1 and X2 (by dragging the vertical red lines) and verify that this result holds whatever their distributions.
Click Accumulate then click Take sample a few times to select pairs of random values
from the two distributions. Observe that the distributions conform reasonably to the theoretical distributions.
Select Difference from the pop-up menu and repeat with the difference between X1 and X2. Note in particular that:
If µ1 = µ2, then X1 - X2 has a normal distribution with mean zero.
11.2.3 Sum and difference (cont)
Different standard deviations
Similar results to these on the previous page
also hold if X1 and X2 have different standard deviations. The table below generalises the formulae on that page.
Note that, as before, the difference between the variables has the same standard deviation as their
sum.
In terms of variances
The formula for the standard deviation can be remembered more easily if expressed
in terms of the variances of the three quantities rather than
their standard deviations. (Remember that the variance is simply the square of
the standard deviation.)
Illustration
The diagram below is similar to that on the previous page but the standard deviations of X1 and X2 can be separately changed by dragging the short vertical lines above their normal distributions. (The means can also be adjusted by draggin the longer vertical lines.)
Again investigate how the distributions of the sum and difference of X1 and X2 are affected by the two means and standard deviations.
In particular, note that:
The standard deviations of X1 + X2 and X1 - X2 are equal and are greater than both σ1 and σ2.
Heights of husband-and-wife pairs
The diagram below simulates sampling a husband and wife from a population where
the husband's height is normal with mean 1.85 metres and the wife's height is
normal with mean 1.7 metres. It is assumed that there is no tendency for tall males to marry tall
females and vice versa — the male and female heights are independent — and that the
distributions for both sexes have standard deviation 0.1 metres.
The distributions on the top right show the clearance of a randomly selected
male and female from a door frame that is 2.1 metres high. These distributions
also have standard deviation 0.1 metres.
Click Accumulate then click Take sample a
few times to select different couples.
(Click on any cross in the jittered dot plots to display the
husband and wife that gave rise to it.)
The mean male height is 0.15 metres greater than the mean female height, so
the distribution of differences (male minus female) is centred on 0.15 metres.
Observe also that the difference has greater standard deviation than either the
male or female heights on their own.
The distance between the top of the woman's head and a fixed
location (the ground or door frame) has lower spread than the distance to a variable
location (the top of the man's head).
11.2.4 Probabilities for sums and differences
Finding probabilities
We often need to find the probability that the sum or difference of two measurements will be within a particular range — for example, the probability that the difference between the heights of two randomly selected people is greater than 20 cm.
If two random variables, X1 and X2, have normal distributions with means µ1 and µ2 and standard deviations σ1 and σ2, their sum and difference are also normally distributed with mean and standard deviation given by the formulae
To obtain probabilities relating to the sum or difference, any value
x
should first be translated into a z-score.
Probabilities relating to this z-score can be obtained from a standard normal distribution. The examples below illustrate the method.
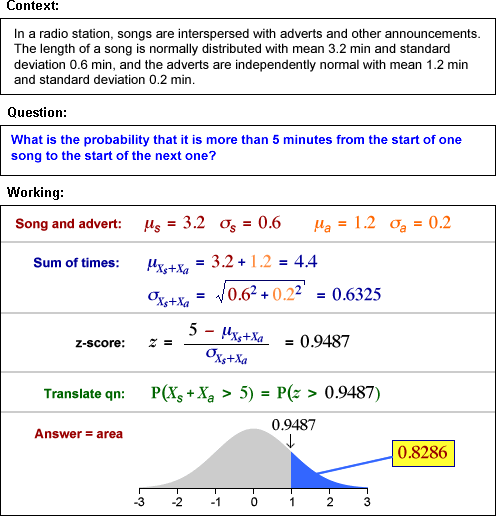
Example (total of several variables)
The following example shows how to find a probability relating to the total of the values in a random sample. (Note that the final step of finding the area under the standard normal density could be found from normal tables or on a computer.)
Example (sum of two variables with different sd)
The next example applies a similar method to a problem concerning the sum of two variables with different standard deviations.
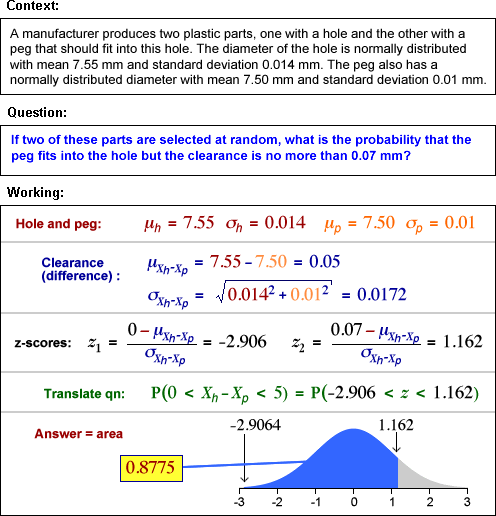
Example (difference between two variables)
The final example involves the difference between two variables
11.3 Comparing means in two groups
Distn of difference between means
SE of difference between means
CI for difference between means
Testing a hypothesis
One-tailed tests for differences
11.3.1 Distn of difference between means
Distribution of difference between sample means
In the previous section, we saw that the difference between two independent
quantities X1 and X2 has a distribution with mean and standard deviation
We can apply this to obtain the distribution of the difference between the
means of two random samples.
Shape of the distribution
If the distributions are normal in each group, ...
... the two sample means have normal distributions, and their difference is
also normally distributed.
If the distributions are not normal in the two groups, ...
... the Central
Limit Theorem states that the distributions of the two sample means approach
a normal shape when the sample size increases, so their difference also approaches
a normal shape.
In general therefore,
Irrespective of the distributions within the two
groups,
Simulation: Manipulative skills of job applicants
The diagram below models an experiment in which a sample of male college students and a sample of experienced female industrial workers were asked to perform a manipulative task involving insertion of pins into a board. The number of pins inserted in one minute was recorded from each subject.
(The means and standard deviations are those obtained from an actual experiment that was described earlier.)
Click Accumulate then take several samples. Observe that the
empirical distribution of the difference between the means matches the theoretical
pink normal distribution.
11.3.2 SE of difference between means
Estimating difference between population means
In most situations where data are collected from two groups, the most important
questions relate to the difference between the population means in the groups.
Since the population means are usually unknown, the sample means are used to estimate
them,
is a point estimate of µ2 - µ1
Error distribution
As in other estimation situations, is
a point estimate of µ2 - µ1 and
is unlikely to be exactly equal to the population difference. In order to properly
interpret its value, we must understand the distribution of the estimation error.
From the results on the previous page,
Unfortunately the population standard deviations in the two groups are also
unknown, so this result cannot be directly used. However they can be replaced
by the sample standard deviations to obtain an estimate of the error distribution,
This distribution gives a reasonable indication of size of the likely errors
and its standard deviation is the standard error of the estimator.
Examples
The diagram below shows the point estimate of the difference between the means
of two groups for a few data sets. The estimated distribution of the estimation
error is also displayed in pink.
In each case, the error distribution gives a reasonable idea of the accuracy
of the point estimate.
11.3.3 CI for difference between means
Interval estimate
A point estimate of µ2 - µ1 cannot be easily interpreted on its own. The estimated error distribution that
was shown on the previous page helps, but statisticians commonly use an interval
estimate instead — a range of values within which we are confident that the true
value of µ2 - µ1 will lie.
If population standard deviations were known...
From the normal distribution of the error, we can state that
If we knew the values of the two parameters
σ1 and
σ2,
we could therefore obtain a 95% confidence interval for
µ2 - µ1 as
Confidence interval for difference
Unfortunately, neither σ1 nor σ2 are known in most practical applications, so we must replace them by their
sample equivalents in the confidence interval. As a result, the constant '1.96'
must also be replaced by a slightly larger value from t-tables,
where the degrees of freedom for the t-value are
(Interval estimates obtained in this way actually have
a confidence level that is slightly higher than 95% — they are conservative estimates.
Some authors prefer a different formula for the degrees of freedom that gives
a slightly lower t-value, but the difference is usually negligible.)
Examples
The diagram below shows how a confidence interval is obtained and interpreted
for the difference between the means of two groups. Use the pop-up menu to see
other data sets.
Properties
Confidence intervals for the difference between two group means have the same
properties as the confidence intervals that we investigated in earlier sections.
A confidence interval that is obtained using the above formula varies from sample
to sample and:
The confidence interval will include the true
difference, ,
in approximately 95% of such repeat samples.
Demonstration of properties
The simulation below shows that 95% confidence intervals vary from sample to
sample, and that not all of them include the true difference between the population
means.
Group B has a population mean that is 10 greater than the mean of group A. Click
Accumulate then take 100 or more samples from the two populations.
Observe that approximately 95% of the resulting confidence intervals for
include the true value (10).
11.3.4 Testing a hypothesis
Testing for a difference between the two population means
When samples are obtained from two groups, we often want to assess whether there is
any evidence of a difference between the groups. Differences between the groups may involve
differences between the spreads, skewness or other features of the distributions in the two
groups. However the difference of most practical importance is a difference between the
means of the groups.
The summary statistic that throws most light on these hypotheses is the difference
between the sample means,
.
Testing therefore involves assessment of whether this difference is unusually far from zero.
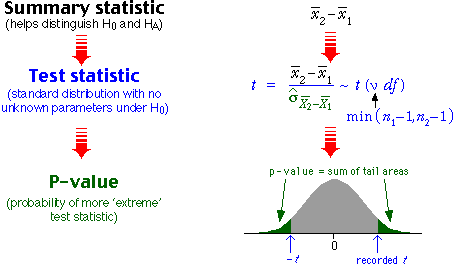
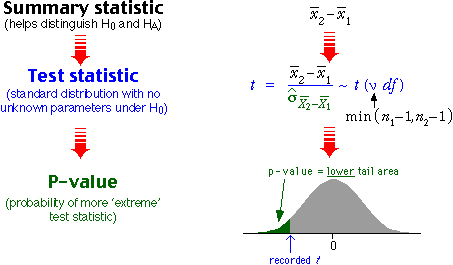
Test statistic and p-value
The difference
is standardised (by dividing by an estimate of its standard deviation) and
this t-statistic is compared to a t distribution, as shown in the diagram
below.
As with all other hypothesis tests, a p-value near zero gives evidence that
the null hypothesis does not hold — evidence of a difference between the group
means.
The p-value is the probability of getting sample
means as different as those observed if the two groups really had the same population
means.
Examples
The diagram below shows how the p-value for testing whether the means in two
groups are the same is evaluated and interpreted.
Use the pop-up menu to examine other data sets.
Properties of p-values
It is important to understand that a statistical hypothesis test cannot provide
a definitive answer about whether two groups have different means. The randomness
of sample data means that:
p-values are also random quantities, and
there is some chance of us being misled by an 'unlucky' sample.
Simulation when the underlying means are the same (H0 is true)
The diagram below allows samples of size 20 to be selected from two populations, both
of which are normal with mean 75 and standard deviation 8.
Take several samples and observe the variation in the resulting p-value. The
p-values are usually greater than 0.1, so we would usually
conclude that there is no evidence of a difference between the means.
However about 1/10 of the p-values are less than 0.1,
1/20 are less than 0.05 and 1/100
are less than 0.01.
There is a (small) probability of getting random
data that misleadingly suggest that the means are different.
Simulation when the underlying means are different (HA
is true)
In the next simulation, the underlying population means are 70 and 80 — a
difference of 10.
Again take several random samples from the model. Observe that the p-value
is usually very close to zero and we usually
conclude that there is strong evidence that the population means are different.
However occasionally the sample means are closer and the p-value
is larger.
There is a chance of getting a large p-value and
concluding that there is no evidence of a difference.
Effect of sample size on the chance of making a 'wrong' conclusion.
There are two types of possible error when reaching a conclusion with a hypothesis
test. It is instructive to note how increasing the sample size affects the probabilities
of these two types of error.
(The results hold for all types of hypothesis
test, not just for comparisions of two population means.)
If the population means are really the same (H0 holds):
There is always probability 0.01 of getting a p-value of 0.01 or lower, irrespective
of the sample size. Increasing sample size therefore does not reduce the
chance of making this sort of error.
If the population means are really different (HA holds):
As the sample size increases, the p-value becomes closer to zero — the probability
of getting a p-value below 0.01, say, approaches 1. If the population
means really are different, increasing the sample size makes you more likely to
detect this difference.
11.3.5 One-tailed tests for differences
Two-tailed tests for differences
The hypothesis tests on the previous page were appropriate for situations
with some kind of symmetry between our attitudes towards the two groups — the
alternative hypothesis did not specify any sign for the difference between the population
means. This type of test is a two-tailed test since test statistics
in both tails of the t distribution suggest that the alternative hypothesis
holds.
Examples of two-tailed tests
Question
Alternative hypothesis
A supermarket chain has two branches
in a town. Based on the individual sales in one day, do shoppers at both branches
tend to have equally large bills?
Mean bills are different in the
two branches
Material is produced by two looms in
a textile mill. The number of flaws in the material from each loom is counted
each day for a month. Does either loom produce material with fewer flaws?
Mean number of flaws per day are different
for the two looms
A lecturer has two accounting classes
and teaches each class about automated accounting systems in a different way.
From each student's mark in a test, is there any evidence about which teaching
method is better?
Mean marks are different for the two
teaching methods
One-tailed tests for differences
In other situations, we want to test whether one specific group has a higher
mean than the other group. Alternatively, we may want to test whether one specific group
has a lower mean than the other group. These are called
one-tailed tests.
Examples of one-tailed tests
Question
Alternative hypothesis
A plumbing firm is concerned about
the time it takes some residential customers to pay for work. It wonders whether
mailing reminders for each overdue account more regularly will help encourage
customers to pay promptly. Half of the overdue accounts are sent monthly reminders
(the current practice) and the other half are sent reminders fortnightly. Is
average time to payment of the accounts reduced?
Mean time to payment is lower for
the fortnightly reminders
A third of the employees in a software
company are randomly selected for a training course. Two weeks after the course,
all employees are asked to rate their satisfaction with their job on a scale
of 0 to 10. Did attendance at the training course improve job
satisfaction?
Mean rating after course is higher
Test statistic and p-value
The test statistic for a 1-tailed test is identical to that for a 2-tailed
test, but the p-value is obtained from only one tail of the t distribution. We
illustrate below for testing the hypotheses,
The alternative hypothesis is only supported by very small values of .
This also corresponds to small values of the test statistic t ,
so the p-value is the lower tail probability of the t distribution.
Examples
The diagram below shows how the p-value is evaluated and interpreted for a
1-tailed test.
Use the pop-up menu to examine other data sets.
Properties of p-values
We again stress that a statistical hypothesis test cannot provide a definitive
answer. The randomness of sample data means that:
p-values are also random quantities, and
there is some chance of us being misled by an 'unlucky' sample.
Simulation when the underlying means are the same (H0 is true)
The following simulation is like one on the previous page, but a 1-tailed test
is used to compare the population means. Samples of size 20 are again selected
from two populations, both of which are normal with mean 75 and standard deviation
8.
Take several samples and observe the variation in the resulting p-value. Again
observe that the p-values are usually greater than 0.1, so we
would usually conclude that there is no evidence that
is higher than .
However about 1/10 of the p-values are less than 0.1,
1/20 are less than 0.05 and 1/100
are less than 0.01.
There is a (small) probability of getting random
data that misleadingly suggest that the second group mean is higher.
11.4 Comparing two proportions
Modelling two proportions
Distribution of difference in proportions
CI for difference in proportions
Testing for difference in probabilities
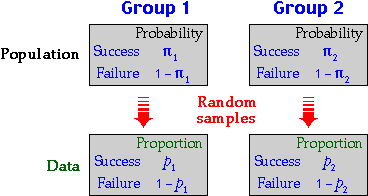
11.4.1 Modelling two proportions
Modelling two-group data
For data that consist of independent samples from two groups, we use a separate
univariate model for each group.
The data in each group are separately modelled as a random sample
from a univariate distribution.
The details depend on the type of measurement from each group.
Numerical measurements
A numerical distribution (e.g. a normal distribution) is used to model each
group. The earlier sections of this chapter described models of this form and
related inference.
Categorical measurements
In each group, the data are assumed to be a random sample of categorical values
from a population whose population proportions (probabilities) are usually unknown.
Categorical measurements with only two categories
In this section, we will consider a special case in which there are only two
possible categories that we generically denote by 'success' and 'failure'.
Are the two groups the same?
We are often interested in differences between two groups. The model for two-group
'success/failure' data involves only two parameters, π1
and π2,
so we will assess the difference between the probabilities, π2 - π1.
If this difference is zero, then both groups are the same.
The value of π2 - π1
concisely describes any difference between the two groups.
In practice, the value of π2 - π1
is unknown, but it can be estimated from sample data. The difference between the
sample proportions, p2 - p1,
is an estimate. However p2 - p1
is a random quantity that varies from sample to sample, so its variability must
be taken into account when interpreting its value.
Typical data sets
The diagram below shows a few data sets in which either 'success' or 'failure'
is recorded from each individual in two groups.
Each data set is summarised by a contingency table.
Note that the red questions do not refer to the specific individuals in the
study. They ask about differences between the groups 'in general'.
We are interested in the population difference π2 - π1
rather than the sample difference p2 - p1. We need to understand the accuracy of our point estimate.
Simulation of sample-to-sample variability
The diagram below selects samples of size 100 from each of two categorical
populations.
Initially the probability of a success in Group A is π1 = 0.30,
so we expect 30 successes and 70 failures from a sample of 100
values. In Group B, π2 = 0.40,
so we expect 40 successes. The table above shows these expected counts and a random
sample from the model.
Click Take sample a few times to observe the variability of
the sample counts of successes and failures. The sample proportions and their
difference are shown on the right.
The difference, p2 - p1,
varies from sample to sample and is often not equal to the population difference,
π2 - π1.
Finally, use the two sliders to adjust the values of the population probabilities,
π1 and π2.
Observe that:
If π1 and π2 are the same, positive and negative values for p2 - p1 occur similar numbers of times — its distribution is centred on zero.
We will examine the distribution of p2 - p1 more carefully in the next page.
11.4.2 Distribution of difference in proportions
Distribution of a single proportion
We saw
earlier that a single sample proportion p
has a distribution with mean and standard deviation
and the distribution is approximately normal in large samples.
This result holds separately for the proportions in each group.
Since the individual proportions are approximately normal (in large samples),
their difference is also approximately normal:
Illustration
The diagram below selects samples of size 100 from each of two groups. The
probabilities of success in the groups can be adjusted using the sliders at the
top.
The normal approximations to the distributions of the individual sample proportions
are shown on the right and the normal approximation to the distribution of the
difference is shown in pink at the bottom.
Click Accumulate and take several samples. Observe that the
sampling variability of the proportions and their difference match the theoretical
distributions reasonably.
Note also that the distribution of the difference has greater spread than that
of the individual proportions.
11.4.3 CI for difference in proportions
Estimating the standard error
The most important parameter of the distribution of p2 - p1
is its standard deviation. This is also the standard deviation of the estimation
error when p2 - p1
is used to estimate π2 - π1
— the standard error of the estimate.
Unfortunately the parameters π1
and π2
are unknown in practical situations. However we can replace them by their sample
equivalents to estimate the standard error.
Confidence interval for difference
The accuracy of our estimate of π2 - π1
depends on its standard error and is best described by a confidence interval.
Any normally distributed quantity has probability 0.95 of being within 1.96
standard deviations of its mean, so
This equation would suggest a 95% confidence interval for
π2 - π1
of the form
However since this formula depends on the unknown values, π1
and π2,
it cannot be used. Instead, we replace them in the formula with their sample equivalents
to obtain a rough confidence interval
The refinement of replacing the constant 1.96 by a t-value,
as was done when comparing population means, is not appropriate here. When the
sample sizes are small, the distribution of p2 - p1
is noticably discrete so the equations underlying the confidence interval, which
are based on a normal approximation, may be quite inaccurate. As a result, we
should avoid this type of confidence interval when sample sizes are small and
we use the value '2' instead of '1.96' to acknowledge the roughness of the formulae.
Examples
The diagram below shows how 95% confidence intervals are found and interpreted
for a few data sets.
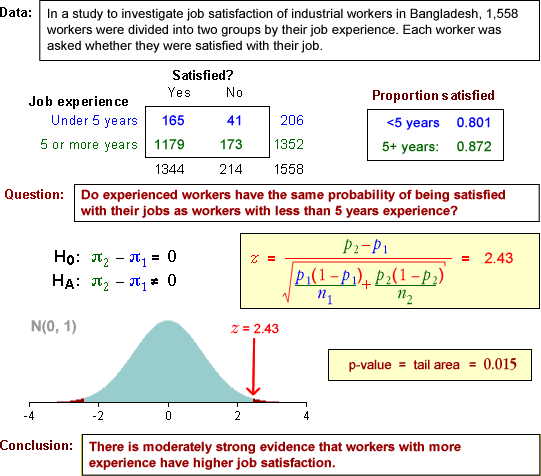
11.4.4 Testing for difference in probabilities
Testing whether the probabilities are different
Testing for a difference between the population probabilities of 'success' in two
groups is based on the sample proportions. Standardising the sample difference provides
a test statistic that can be compared to the standard normal distribution to obtain
an approximate p-value for the test.
Two-tailed test
Firstly, consider the two-tailed test,
The steps involved in obtaining a p-value for this test are shown in the
diagram below
The p-value is interpreted in the same way as for all previous tests. A p-value close to
zero is unlikely when H0 is true, but is more likely when HA
holds. Small p-values therefore provide evidence of a difference between the population
probabilities.
One-tailed test
For a 1-tailed test, the alternative hypothesis is that π2
is only on one side of π1.
The test statistic is identical to that for a 2-tailed test and the p-value
is obtained in a similar way, but it is found from only a single
tail of the standard normal distribution.
Alternative test statistic
Most statisticians prefer
to use a different formula for the standard deviation in the evaluation of the
z-value above. Since π1
and π2
are equal if H0 is true, the overall proportion of successes,
p,
can be used in the formula for the standard deviation of p2 - p1.
This refinement makes little difference in practice, so
the examples below use the 'simpler' formula that we gave earlier.
Examples
The diagram below shows how the p-values and conclusions are obtained for a
selection of 1- and 2-tailed tests.
11.5 Paired t test
Paired data
Analysis of differences
Paired t-test
Pairing and experimental design
11.5.1 Paired data
Paired data
The statistical methods for analysis of data depend strongly on the structure
of the data and how the data were collected. We now consider how to analyse
a different type of data.
When two types measurements, X and Y, are made from each
individual (or other unit), the data are called bivariate.
In many bivariate data sets, the two variables describe quantities on different
scales, such as height and weight, but sometimes the two measurements are
of more closely related quantities. The two measurements may even describe
the same quantity at different times.
When the sum or difference of X and Y is
a meaningful quantity, the data are called paired data.
With paired data, we could investigate the relationship between the variables,
but we are often more interested in whether the means of the two variables
are the same.
Pre-test, post-test data
To evaluate the effectiveness of a training exercise, it is common for individuals
to sit similar tests before and after the training. There is usually considerable
variation in the abilities of the participants, so the pre-test and post-test
scores will be related. However it is or more interest to ask:
Has the mean score improved?
Data with a similar structure arise when measurement are made from individuals
before and after any type of change (experimental or otherwise).
In a warehouse, the employees have asked management to play music to relieve the
boredom of the job. The manager wants to know whether efficiency is affected by
the change. The table below gives efficiency ratings of 15 employees recorded
before and after the music system was installed.
Efficiency rating
Efficiency rating
Employee
Before
After
Employee
Before
After
1
2
3
4
5
6
7
8
21
35
40
38
23
27
28
39
32
35
38
57
37
30
39
28
9
10
11
12
13
14
15
22
35
28
20
39
28
34
40
48
33
33
39
41
40
Has efficiency changed?
Twin studies
Many characteristics of individuals are determined by genetics, but many others
are affected by their environment. There are therefore many studies of monozygous
twins (genetically identical) who have been raised apart.
The table below shows the IQs of ten pairs of twins who were raised apart.
In each pair, one twin had been raised in a 'good' environment and another in
a 'poor' environment.
IQ
Family
Poor environment
Good environment
1
2
3
4
5
6
7
8
9
10
100
65
60
125
85
145
55
180
60
135
125
95
100
120
120
185
80
210
105
175
The genetic influence on IQ is evident — when one twin has high IQ, the other
often does too. However we can also ask...
Do the twins raised in a 'good' environment have a different
mean IQ from those raised in a 'poor' environment?
Although twin studies are uncommon in business research, the 'individuals'
under investigation (employees, retail outlets, creditors, ...) are often grouped
into pairs that are as similar as possible before an experiment is conducted.
For example, a chain of fast-food outlets is researching which of two new types
of hamburger will be more popular. Pairs of outlets are selected that have similar
sizes and turnovers and are in areas with similar socio-economic status. The two
new hamburgers would each be trialed in one of the outlets in each pair.
Other paired data
The measurements may be paired by other mechanisms. An insurance company is
concerned that garage A is charging too much for repairing damage to cars. Ten
damaged cars were taken to both garage A and another garage for estimates. The
table below shows the estimates for repairing the cars (in dollars).
Repair estimate
Car
Garage A
Garage B
1
2
3
4
5
6
7
8
9
10
420
900
1260
630
240
1080
1460
1900
2020
1520
380
760
1180
560
260
1000
1300
1720
1800
1440
The estimates from the two garages are clearly related — some cars are more
badly damaged than others. Of more interest is the question...
Is the mean estimate higher for garage A than for garage B?
Many other data sets contain measurements that are paired in similar ways.
Hypotheses of interest
For paired data, the most interesting hypotheses relate to the means of the
two variables, X and Y, and often we want to test whether they
are equal.
Sometimes a one-tailed test is required, such as
The null hypotheses in the examples above would be
Effect of music on efficiency
IQ and environment
Repair estimate and garage
11.5.2 Analysis of differences
Differences
The key to analysing paired data is to recognise that the differences
between X and Y hold all the information about whether their
means are the same. Writing
D = Y - X
the hypotheses
can be expressed as
This reduces the paired data set to a univariate data set of differences. The
test also becomes a simpler hypothesis test about the mean of these differences.
Music and work efficiency
The increase in efficiency for each employee (after the music system was installed)
is shown in the final column below.
Efficiency rating
Employee
Before
After
Difference
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
21
35
40
38
23
27
28
39
22
35
28
20
39
28
34
32
35
38
57
37
30
39
28
40
48
33
33
39
41
40
11
0
-2
19
14
3
11
-11
18
13
5
13
0
13
6
Is the mean of the differences zero?
Twin studies
The final column below shows the difference in IQ for each pair (good minus
poor)
IQ
Family
Poor environment
Good environment
Difference
1
2
3
4
5
6
7
8
9
10
100
65
60
125
85
145
55
180
60
135
125
95
100
120
120
185
80
210
105
175
25
30
40
-5
35
40
25
30
45
40
Is the mean of the differences zero?
Garage repair estimates
The final column shows the amount that garage A overcharges, compared to garage
B.
Estimate for car repair
Car
Garage A
Garage B
Difference
1
2
3
4
5
6
7
8
9
10
420
900
1260
630
240
1080
1460
1900
2020
1520
380
760
1180
560
260
1000
1300
1720
1800
1440
40
240
80
70
-20
80
160
180
220
80
Is the mean of the differences zero?
Analysis of paired data
By taking differences, much of the variability between the individuals is eliminated.
This provides considerably more information to help assess the null and alternative
hypotheses.
The benefits of pairing will be explained more fully in a later page.
Garage repair estimates
The diagram below shows the repair estimates from garages A and B.
The two distributions overlap considerably due to variability in the amounts of
damage to the cars, so it initially appears that there will be little evidence
against equal means.
Click on individual crosses to show the difference between the estimates for
individual cars. Most estimates are higher for garage A.
Click Show Pairing to draw lines between the pairs of crosses
and display the differences in a jittered dot plot. The differences give much
clearer evidence that the mean estimate is higher for garage A — it seems that
the mean difference is positive.
Note that it would be wrong to analyse this as two separate samples:
The data are paired because each pair of repair estimates is for the same car.
11.5.3 Paired t-test
Approach
We have seen that the problem of testing whether two paired measurements, X
and Y, have equal means is done in terms of the differences
D = Y - X
The test is then expressed as
H0: µD = 0
HA: µD ≠ 0
or a one-tailed variant. This is a standard univariate hypothesis test of the
form analysed in the previous section.
Paired t-test
The hypotheses are therefore assessed with a standard t-test. The test statistic
is
and it is compared against a t distribution with n - 1 degrees
of freedom to find the p-value.
Estimated and actual costs for projects
A construction company is concerned that it is underestimating the costs of
the projects for which it is bidding. To help assess this, the company selected
a sample of 20 recently completed projects for review. Data were obtained about
the actual labour costs for the projects (in thousands of hours) and the estimated
costs at the time of the bid.
The data are paired since the actual and estimated costs come from the same projects.
We are testing to see if there is evidence that the estimates are too low, a one-tailed test. Denoting the difference (actual – estimate) by D, we are looking for evidence that µD > 0 (meaning that the actual cost tends to be higher than the estimate). The hypotheses are therefore:
H0: µD = 0
HA: µD > 0
The diagram below shows the differences on the left. The p-value for the test is calculated on the right.
Since the p-value for the test is very close to zero (0.003), there is strong
evidence from these projects that labour costs are being underestimated.
Select Modified Data from the pop-up menu, then use the slider
to investigate how low the mean actual labour cost would need to be for there
to be little evidence of a difference.
Music and work efficiency
In this example, a measurement of efficiency was made from employees both before
and after a music system was installed. The data were tabulated at the start of
this section and are graphed below.
Here we use a two-tailed test as the music may either increase or decrease efficiency. Denoting the difference for each employee as D = (after - before), we are therefore interested in the hypotheses:
H0: µD = 0
HA: µD ≠ 0
The p-value for this test is calculated on the right below.
The resulting p-value is
very small, giving strong evidence that efficiency has changed. The test only gives evidence of a difference in the mean efficiencies. However the positive t value suggests µD > 0, so it is valid to conclude that there is evidence of an increase in efficiency after the system was installed.
Again, select Modified Data and investigate how different
the sample means must be to give evidence of a difference in the population means.
11.5.4 Pairing and experimental design
Choice between paired data or two independent samples
It is sometimes possible to answer questions about the difference
between two means by collecting two alternative types of data.
Two independent samples
Measurements are made from two samples of individuals from the groups
whose means are to be compared. A 2-sample t-test will compare the means.
One paired sample
The 'individuals' can be re-defined as pairs of related values from the
two groups, and a single sample of these pairs can be collected. A paired
t-test can be performed on the differences to compare the means.
Which experimental design is better?
If the individuals in the 2 groups can
be paired so that the pairs are relatively similar, a paired design gives
more accurate results.
Car repair costs from two garages
Consider an insurance company that is investigating whether Garage B is
over-charging for car repairs. Data should be collected to compare the average
estimates for repairs from Garage B and another garage, Garage A.
Simulation
We will conduct a simulation based on a pool of 20 cars. In the simulation, all repair estimates are normally distributed with standard deviation σ = $120, but with means shown in the table below
Note that Garage B over-charges by align="CENTER"00 on average
for each car.
Two independent samples
We first simulate an experiment in which 10 cars are randomly selected
to be sent to Garage A, and the other 10 cars are assessed by Garage B.
A 95% confidence interval for the over-charging (difference between the
mean estimates from the two garages) is shown, and the p-value for a 2-tailed
test for a difference is also given.
Repeat the simulation several times and observe from the p-values that:
The 2-sample test rarely gives evidence that Garage
B over-charges — the p-value is usually over 0.05.
Click Show paired values to see the (unobserved) data
that would have been obtained if all cars had been assessed by all garages.
Paired data
We next simulate an experiment in which 10 cars are randomly selected and
are assessed by both Garage A and Garage B.
A 95% confidence interval of the over-charging is again shown, this time
based on the differences between the estimates in the pairs. The p-value
for a 2-tailed paired t-test for a difference is also given.
Repeat the simulation several times and observe from the p-values that:
The paired t-test usually finds strong evidence that
Garage B over-charges.
Matched pairs in experiments
It is often impossible to repeat the same experiment twice with the same
experimental units. In the Car Repair Costs example, if the comparison was
to be made of actual repair costs rather than estimates,
it would be impossible to obtain measurements for the same car from both garages.
However it is often possible to group together the experimental units into
pairs that are similar in some way. These are called matched pairs.
The two experimental units in each pair are randomly assigned to the two treatments.
Actual car repair costs from garages A and B
The damaged cars could be grouped into pairs with similar types of damage.
The two cars in each pair would be randomly sent to the two garages for
repair.
Do students perform better in a test before or after lunch?
Each student should only sit the test once. However the students could
be grouped into pairs, based on their IQ or their results in earlier tests.
In each pair, a randomly selected student would sit the test before lunch
and the other would sit after lunch.
Effect of fertiliser on grass growth
Six fields in different parts of an agricultural research station are
available for an experiment to estimate the increase in grass growth from
applying a standard quantity of fertiliser. Each field can be split in
half to form 'pairs' of half-fields for the experiment. Fertiliser would
be applied to a randomly selected half of each field.
In each example, pairing gives more accurate estimates than randomly allocating
the units (cars, students or fields) to the two treatments if the units
in the pairs are more similar to each other than to units in other pairs.
11.6 Comparing several means
Model
Parameter estimates
Revisiting two groups
Variation between and within groups
Sums of squares
Coefficient of determination
Test for differences between groups
Examples
11.6.1 Model
Data sets with several groups
Problem
Data collected
Randomisation
A manufacturer of breakfast cereals want
to introduce a new meusli and wonders which of 3 recipes to use.
150 people in a supermarket are each asked
to taste one of the recipes and give it a score between 1 and 10.
Customers must be randomly given one of
the 3 recipes.
An investor wants to know which of four
types of mutual fund is likely to give the highest return.
Ten funds of each type are selected and
their returns over the previous year is determined.
The selected funds should be randomly selected
from a list of funds of each type.
An lecturer wants to know whether there
are differences between the effectiveness of the tutors in a course.
Final exam marks from all students are
grouped by the six different tutors.
It must be assumed that the students were
randomly allocated to tutors.
Data of this form can be considered as either:
A separate sample of numerical measurements from each of g groups,
or
Bivariate data with a numerical response and a categorical 'explanatory' variable
with g levels that identifies group membership.
In
an earlier section, we used the following model when comparing the means of
two groups.
Group 1:
Y ~ normal (µ1 , σ1)
Group 2:
Y ~ normal (µ2 , σ2)
We also presented methods for inference about the difference between the two
group means.
The most obvious extension of this model to g > 2 groups
would allow different means and standard deviations in all groups.
Group i:
Y ~ normal (µi , σi)
Same standard deviation in all groups
Extending the test for equal group means from 2 to g > 2
groups requires an extra assumption in the model. We must assume that the standard
deviations in all groups are the same.
Group i:
Y ~ normal (µi , σ)
If there are g groups, the model has g + 1 unknown
parameters — the g group means and the common standard deviation, σ.
This model is flexible enough to be useful for many data sets.
If the assumptions of a normal distribution and constant
variance do not hold, a nonlinear transformation of the response may result in
data for which the model is appropriate.
Illustration of the model
The diagram below shows a normal model for g = 3 groups.
Initially, the diagram allows the flexibility of separately adjusting the 3 means
and 3 standard deviations using the sliders.
Click the checkbox Equal st devn to restrict the model by
constraining the 3 standard deviations to be the same. This reduces the number
of parameters to 4 — the 3 group means and the common standard deviation. Use
the sliders to see the flexibility of this model.
Rotate the display to look down on the two main axes (click the y-x button).
The normal distributions in the three groups are represented by pale bands stretching
two standard deviations on each side of the group mean, with a slightly darker
band at 0.674 standard deviations on each side of the mean. Click Take
Sample a few times to observe typical data sets that would be obtained
from this model.
Observe that approximately 95% of the values are within the pale blue bands
— about 95% of values from any normal distribution are within 2 standard deviations
of the mean. About 50% of the values are within the darker bands.
11.6.2 Parameter estimates
Estimating the parameters
We now restrict attention to normal models that have the same standard deviation
in each of the g groups.
Group i:
Y ~ normal (µi , σ)
There are g + 1 parameters that must be estimated from the
data. Each group mean can be estimated with the corresponding sample mean,
The sample standard deviation in any single group, si,
is a valid estimate of σ.
How should these g separate estimates be combined to give a single pooled
estimate of σ?
Pooled estimate of variance
It is easier to describe estimation in terms of variance
— the square of the standard deviation
From the data in a single group (say group i), the sample variance
is an estimate of σ2,
If the sample sizes are the same in all groups, the pooled variance is the
average of these group variances,
Mixed sample sizes (optional)
If the sample sizes are not equal in all groups, a more complex formula is
needed. The best estimate of σ2
is found by adding the numerators and denominators of the formulae for the
g separate group variances,
To express this more mathematically, we use two subscripts for each value,
so yij
denotes the j 'th of the ni
values in group i , for i = 1
to g . The pooled estimate of σ2
can then be written as
Illustration of pooled variance
The diagram below shows a random sample from a normal model in which the
group means differ, but all groups have the same variance, σ2 = 0.9.
(The grey bands show the means ± 2 standard deviations for the model.)
Note that the crosses have been jittered a little (moved horizontally) to
separate them within each group.
The vertical coloured lines from the crosses in each group to the group mean
are the values
whose sums of squares are the numerators of the equations for the si2.
The numerator of the pooled estimate of σ2
is the sum of the numerators for the group variances. The denominator is the sum
of their denominators.
Note that the numerator is the sum of the squared lengths
of all coloured vertical lines.
When all group sizes are the same, the pooled estimate is the average of the
three group variances.
Use the pop-up menu to change the sample sizes. Observe that the pooled variance
is closest to the variance in group 1, the biggest group. Note that if one group has only a single observation, then it cannot contribute to the estimate of the pooled variance.
11.6.3 Revisiting two groups
Revisiting the difference between two group means
In this page, we re-examine inference about the difference between two group
means, µ2 - µ1,
but we now assume that both groups have the same standard deviation,
Inference is still based on ,
but the equation for its standard deviation can be simplified
Confidence interval
A 95% confidence interval for µ2 - µ1
has the same general form as before,
However the value used for the standard deviation and the degrees of freedom
for the t-value, ν, are different.
degrees of freedom
Allowing
min( n1
- 1, n2 - 1)
Assuming
n1
+ n2 - 2
When the standard deviations are assumed to be equal, the degrees of freedom
are larger, so the t-value used for the confidence interval is smaller and the
confidence interval itself is usually narrower.
Recommendation
Since the 95% CI for the difference in means is usually narrower when the standard
deviations are assumed to be the same, it might appear that this would be the
best CI to use. However
Big sample sizes:
There is very little difference between the two t-values — both are close
to 2.0. The two CIs are therefore similar.
Small sample sizes:
There is usually not enough data to assess whether the assumption
is justified.
Therefore:
It is usually best to avoid assuming equal standard
deviations and use the earlier confidence interval.
Examples
The diagram below shows 95% confidence intervals obtained by the two methods
for a few data sets.
Observe that the 95% confidence intervals are similar when the sample sizes
are large. When the sample sizes are small however, the t-value is smaller when
the variances are assumed equal and the confidence interval is narrower.
Hypothesis tests
If it can be assumed that ,
the test for equal means can also be modified.
The test would be based on the test statistic
The p-value for the test is found from the tail area of the t distribution
with (n1 + n2 -
2) degrees of freedom. However it is usually better to stick with the earlier
test to avoid making assumptions about the variances.
11.6.4 Variation between and within groups
Comparing several groups
The methods for obtaining confidence intervals and hypothesis tests for two
groups do not extend to comparisons of the means of three or more groups.
A new approach is needed to compare the means of 3
or more groups.
Hypotheses for testing
For the remainder of this section, we assume a normal model with equal standard
deviations.
Group i:
Y ~ normal (µi , σ)
If all means are the same in the model, then there are no differences between
the groups. We are therefore interested in testing the hypotheses,
Variation between and within groups
If the model means are all equal, it would be expected that the sample means
would be similar. However they are unlikely to be identical. We therefore need
to assess whether the variation between the group means is unusually
great. To do this, we must also take account of the variation within the
groups.
We will show in later pages that these two aspects of variation can be described
with summary statistics and used for a hypothesis test.
Variation between groups
The jittered dot plots below show 10 numerical measurements from each of 4
groups.
Use the slider to alter the difference between the group means. Observe that:
When the between-group variation is high, we become more certain that the
differences between the group means could not have occurred by chance.
Variation within groups
The diagram below is similar, but the slider adjusts the spread of values within
each group, leaving the group mean unaltered.
Observe that ...
The lower the within-group variation, the more certain we become that
there really is a difference between the underlying model means.
Are the underlying means equal?
The evidence for a difference between the group means depends on both the
variation between and within groups. It is strongest when:
the between-group variation is relatively high, and
the within-group variation is relatively low.
Signal and noise
In the field of communications, the signal in a recorded
or transmitted message (e.g. music) is defined to be the information in
which we are interested. There is often other variability in the received message that contains no useful information; this variability can potentially obscure or corrupt the signal and is called noise.
Applying this terminology to the comparison of several groups,
Signal
The variation between group means is the signal in the data.
Noise
Variation within groups is noise.
The greater the noise, the harder it is to detect or estimate the signal.
We will next present numerical summaries of the signal and noise in multi-group
data.
11.6.5 Sums of squares
Summarising variation between and within groups
It was explained on the previous page that the evidence for a difference between
the underlying group means is strongest when the variation between group means
is high relative to the variation within groups. In this page,
we describe quantities that summarise these two types of variation.
A little mathematical notation allows us to concisely define these summaries of variation. In each of the g groups, there are several values and we use the notation yi1, yi2, ... to denote the values in the i'th group. In general, the j'th of the response measurements in the i'th group is called yij .
The mean of the values in the i'th group is denoted by .
Total variation
Before summarising variation within and between groups, we first present a
value that describes the overall variability in the response measurement, ignoring
the existence of groups.
The total sum of squares reflects the
total variability of the response.
Note that the overall variance of all values (ignoring the existence of the groups) is the total sum of squares divided by (n - 1).
Variation between groups (signal)
A measure of variation between groups should summarise the distance between
group means. It is defined in terms of distances between the group means and the
overall mean, .
The sum of squares between groups measures
the variability of the group means.
Note that the summation here is over all observations
in the data set — all values in any group separately contribute
the same amount to the between-group sum of squares.
Variation within groups (noise)
The measure of variation within groups summarises the differences between the
values and their group means.
The sum of squares within groups quantifies
the spread of values within each group.
This is also called the residual sum of squares since it describes
variability that is unexplained by differences between the groups. Note that the
pooled estimate of the common variance, σ2,
is the sum of squares within groups divided by (n - g).
Relationship between sums of squares
The following relationship requires some algebra to prove but is important.
Illustration of sums of squares
The display on the left below shows 8 numerical measurements from each of
4 groups.
The three jittered dot plots on the right show the values whose squares are
summed to give the total, between-group and within-group sums of squares. Click
on any of these three plots to display the quantities on the diagram on the left.
The sums of squares summarise the size of the three components.
Use the slider to adjust the data values and observe how the relative size
of the variation between groups and within groups is reflected in the size of
these sums of squares.
Evidence for a difference between the group means is
strongest when the between-group sum of squares is much higher than the within-group
sum of squares.
11.6.6 Coefficient of determination
Sums of squares
The table below summarises the interpretation of the total, within-groups and
between-groups sums of squares.
Sum of squares
Interpretation
Overall variability of Y, taking no account of the groups.
Describes variability around the group means and is therefore variability
that cannot be explained by the model.
Describes how far the group means are from the overall mean — i.e.
the variability of the group means. It can also be interpreted as the
sum of squares explained by the model.
The best prediction for any observation in group i would be
if groups were not taken into account, whereas it would be
with our model.
The between-group sum of squares summarises
how much predictions are improved by using the model.
Coefficient of determination
Since the total sum of squares is the sum of the between-group (explained) and within-group (residual) sums of squares, a useful summary statistic is the proportion
of the total sum of squares that is explained by the model. This proportion is
called the coefficient of determination and is denoted by R2.
Note the following properties of R2.
R2 always has a value between zero and one.
When R2 is close to 1, all values must be relatively close
to their group means. Since the proportion of unexplained
variation is (1 - R2), the unexplained variation must
be relatively low.
When R2 is close to 0, the variability within the groups is
much greater than the variability between the means — the means are similar
to each other.
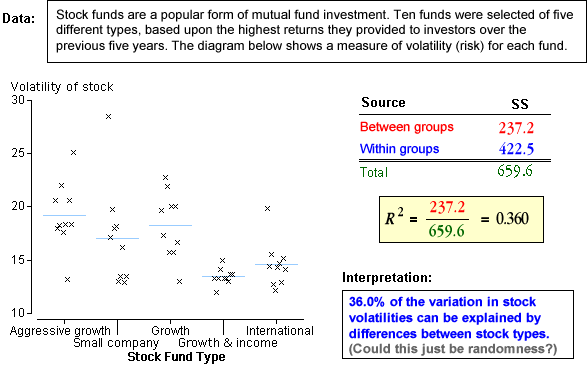
Examples
The diagram below shows how R2 is calculated and interpreted for
a few data sets.
Note that we have not taken into account randomess of the sums of squares.
We cannot conclude from the R2 value on its own whether the underlying
group means are different.
11.6.7 Test for differences between groups
Hypothesis test
The coefficient of determination, R2, summarises the proportion
of variation in the data that can be explained by differences between the groups. It
does not however indicate whether this is bigger than could be expected by chance.
Formally, we want to test whether the group means are the same:
H0 : µi = µjfor all i and j HA: µi ≠ µjfor at least some i, j
This hypothesis test also depends on the sums of squares but uses them in a
different way.
The hypothesis test cannot be fully explained here.
You should use computer software to evaluate the p-value for the test, but we
will briefly describe some of the steps.
Mean sums of squares
The first step in evaluating the p-value for the test is to divide each of
the three sums of squares by a value called its degrees of freedom
to obtain a mean sum of squares.
The mean total sum of squares is the
sample variance of the response (ignoring groups).
The mean within-group sum of squares
is the pooled estimate of the variance within groups.
The mean between-group sum of squares
is harder to directly interpret.
We explained earlier that the total sum of squares equals the sum of the within-group and between-group sums of squares. Note that the same relationship also holds for the degrees of freedom (the denominators of the above definitions) — the total degrees of freedom are the sum of the within-group and between-group degrees of freedom.
F ratio and p-value
The test statistic is the ratio of the between- and within-group mean sums
of square. It is called an F-ratio.
This test statistic compares between- and within-group variation:
The further apart the group means, the bigger the between-group mean sum of
squares and hence the higher the F-ratio.
The lower the variation within each group, the smaller the within-group mean
sum of squares and hence the higher the F-ratio.
Large values of F suggest that H0 does not hold —
that the group means are not the same.
The p-value for the test gives the probability of such a high F ratio if H0
is true (all group means are the same). It is based on a standard distribution
called an F distribution and is interpreted in the same way as
other p-values.
The closer the p-value to zero, the stronger the evidence
that H0 does not hold.
Analysis of variance table
The calculations are usually presented in a table called an analysis
of variance table. (This is often abbreviated to an anova table.)
Illustration of calculations
The dot plots on the left below show 3 numerical measurements from each of
4 groups.
The slider adjusts the relative size of the between-group and within-group
sums of squares. Observe how this affects the p-value for the test.
The greater the proportion of explained variation, the larger the F-ratio and
the closer the p-value becomes to zero.
Use the pop-up menu to increase the sample size and observe that a smaller
amount of explained variation is needed to obtain a small p-value (and hence strong
evidence that the underlying group means are different).
11.6.8 Examples
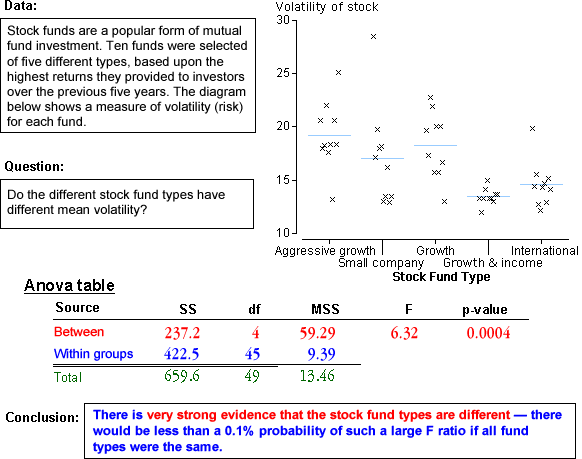
Examples
The diagram below shows how p-value is calculated in an analysis
of variance table and interprets the p-value for a few data sets.